
一、问题引入
最近使用solo编辑博客时,发现特别的卡,并且Linux服务器使用命令也特别不流畅。索性就使用top -c查看了下服务器CPU的使用情况,果然发现solo服务器时高时低,
非常频繁,此时并没有使用服务器。
那么服务器究竟在干什么呢?
对CPU服务器分析,(分析方式记录在博客:服务器项目问题定位—CPU)发现此时solo服务器正在进行线程是jvm线程。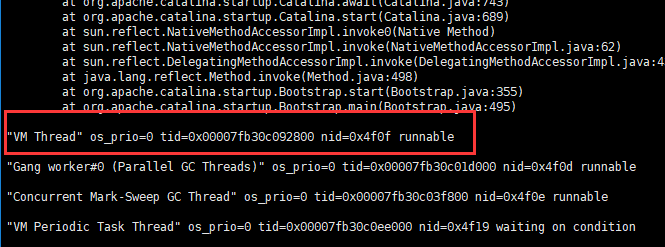
是什么导致jvm频繁使用呢?我首先想到了gc,通过查看gc日志,发现gc日志中存在大量的Full GC,而且特别频发,如图。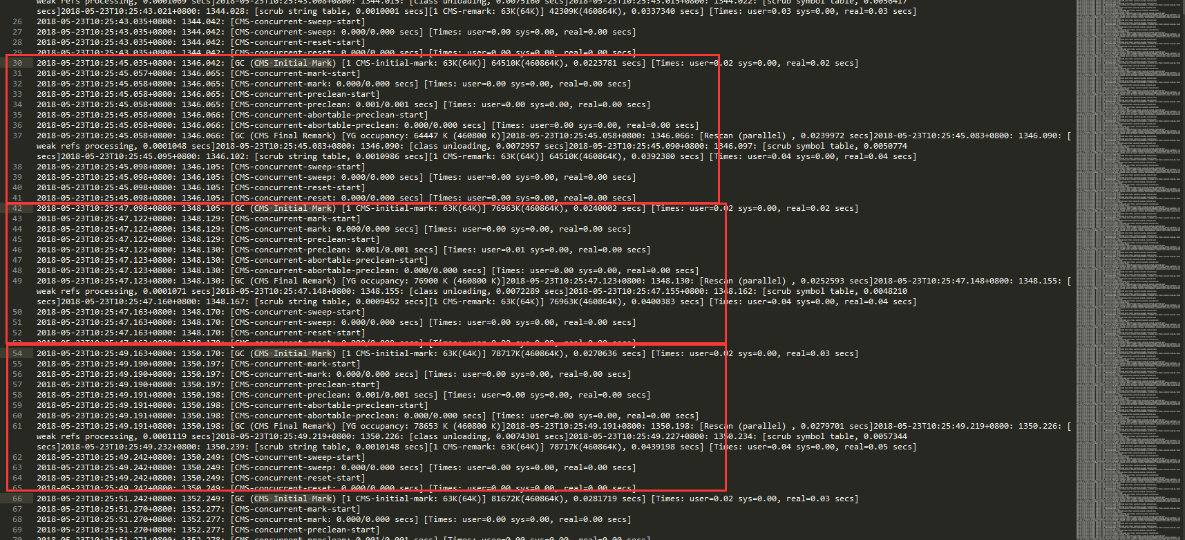
二、GC日志分析
Full GC
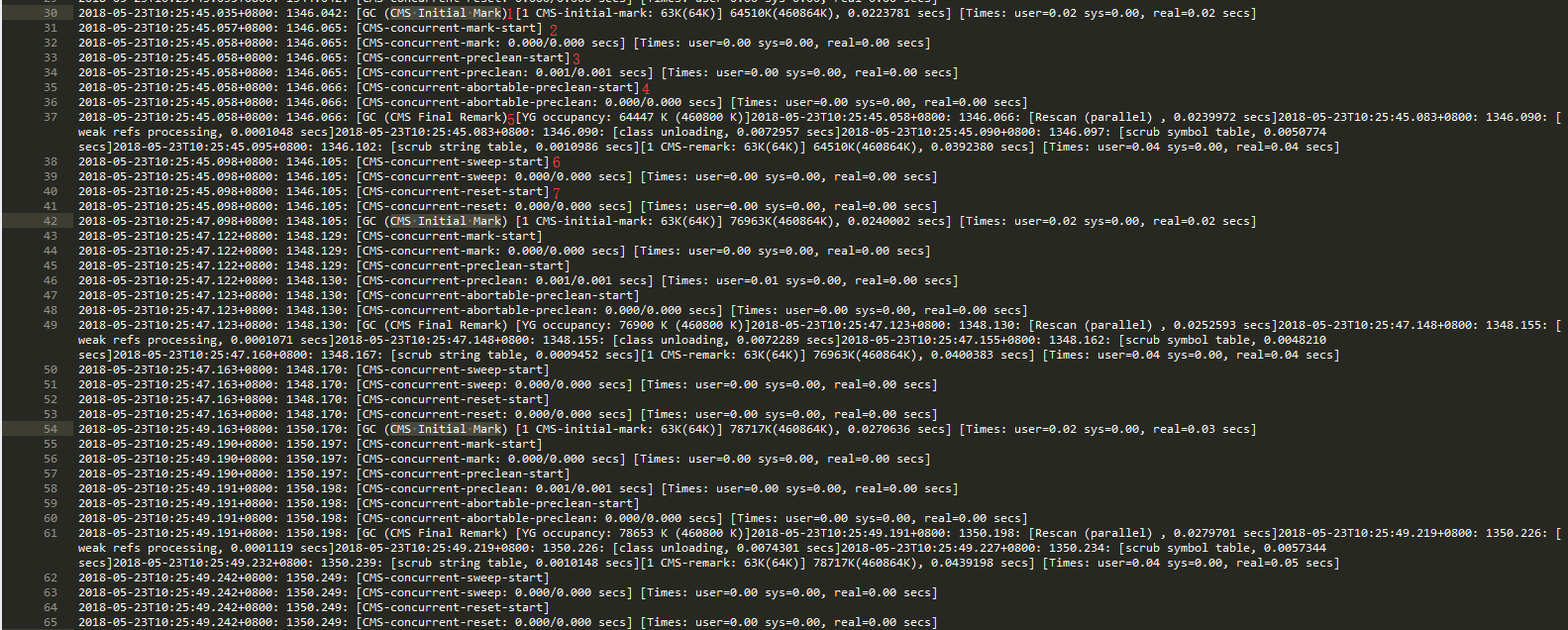
1.Initial Mark
收集阶段,收集所有GC roots和直接引用的对象,执行时会导致stop-the-word。
1
2018-05-23T10:25:47.098+0800: 1348.105: [GC (CMS Initial Mark) [1 CMS-initial-mark: 63K(64K)] 76963K(460864K), 0.0240002 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
2018-05-23T10:25:47.098+0800: 1348.105 :GC开始的时间。
63K(64K): 当前年老代的使用容量(年老代的总容量)。
76963K(460864K):当前堆的使用容量(堆的总容量)。
0.0240002 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] : 执行时间。
2.concurrent-mark
并发收集阶段,多线程遍历标记年老代存存活的对象。与应用线程并行运行,不会中断。
1
22018-05-23T10:25:47.122+0800: 1348.129: [CMS-concurrent-mark-start]
2018-05-23T10:25:47.122+0800: 1348.129: [CMS-concurrent-mark: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]2018-05-23T10:25:47.122+0800: 1348.129:GC开始的时间。
0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]:执行时间。
3.concurrent-preclean
标记前个阶段已经标记过,但是有发生变化的区域为dirty card。与应用线程并行运行,不会中断。
1
22018-05-23T10:25:47.122+0800: 1348.129: [CMS-concurrent-preclean-start]
2018-05-23T10:25:47.122+0800: 1348.130: [CMS-concurrent-preclean: 0.001/0.001 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]解释同上。
4.concurrent-abortable-preclean
确定执行了足够次数的标记,可以进行下个阶段。
1
22018-05-23T10:25:47.123+0800: 1348.130: [CMS-concurrent-abortable-preclean-start]
2018-05-23T10:25:47.123+0800: 1348.130: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]解释同上。
5.Final Remark
该阶段会标记年老代全部的存活对象,包括那些在并发标记阶段更改的或者新创建的引用对象,执行时会导致stop-the-word。
1
2018-05-23T10:25:47.123+0800: 1348.130: [GC (CMS Final Remark) [YG occupancy: 76900 K (460800 K)]2018-05-23T10:25:47.123+0800: 1348.130: [Rescan (parallel) , 0.0252593 secs]2018-05-23T10:25:47.148+0800: 1348.155: [weak refs processing, 0.0001071 secs]2018-05-23T10:25:47.148+0800: 1348.155: [class unloading, 0.0072289 secs]2018-05-23T10:25:47.155+0800: 1348.162: [scrub symbol table, 0.0048210 secs]2018-05-23T10:25:47.160+0800: 1348.167: [scrub string table, 0.0009452 secs][1 CMS-remark: 63K(64K)] 76963K(460864K), 0.0400383 secs] [Times: user=0.04 sys=0.00, real=0.04 secs]
- 2018-05-23T10:25:47.123+0800: 1348.130:起始时间。
- [YG occupancy: 76900 K (460800 K)]:当前年轻代使用容量(年轻代的总容量)。
- [Rescan (parallel) , 0.0252593 secs]:执行标记的总时间。
- [weak refs processing, 0.0001071 secs]:处理弱引用对象。
- [class unloading, 0.0072289 secs]:that is unloading the unused classes, with the duration and timestamp of the phase。
- [scrub symbol table, 0.0048210 secs][scrub string table, 0.0009452 secs]:that is cleaning up symbol and string tables which hold class-level metadata and internalized string respectively。
- [1 CMS-remark: 63K(64K)] 76963K(460864K), 0.0400383 secs]:执行之后年老代的使用容量(年老代总容量),堆的使用容量(堆的总容量)。
- [Times: user=0.04 sys=0.00, real=0.04 secs]:执行时间。
6.concurrent-sweep
清除没有标记的对象,进行回收,不停止应用。
1
22018-05-23T10:25:47.163+0800: 1348.170: [CMS-concurrent-sweep-start]
2018-05-23T10:25:47.163+0800: 1348.170: [CMS-concurrent-sweep: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]7.concurrent-reset
重新设置CMS算法内部的数据结构,准备下一个CMS生命周期的使用。
1
22018-05-23T10:25:47.163+0800: 1348.170: [CMS-concurrent-reset-start]
2018-05-23T10:25:47.163+0800: 1348.170: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]通过日志,我们可以看出年老代总的内存只有64k,严重不足。所以频繁触发Full GC。
三、jvm参数
通过GC日志的分析,我们定位到是由于应用服务器内存分配导致问题。这时候我们需要具体了解下jvm参数都代表什么意思,起到什么作用。
这里我就不全部列举出来了,更多参数也有很多的博客。
堆设置
- -Xms:初始堆大小
- -Xmx:最大堆大小
- -Xmn:设置年轻代大小
- -Xss:设置每个线程的堆大小
- -XX:NewSize=n:设置年轻代大小
- -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
- -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
- -XX:MaxPermSize=n:设置持久代大小
收集器设置
- -XX:+UseSerialGC:设置串行收集器
- -XX:+UseParallelGC:设置并行收集器
- -XX:+UseParalledlOldGC:设置并行年老代收集器
- -XX:+UseConcMarkSweepGC:设置并发收集器
垃圾回收统计信息
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:filename
并行收集器设置
- -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
- -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
- -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
- -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
- -XX:CMSInitiatingOccupancyFraction=70:使用cms作为垃圾回收,当使用70%后开始CMS收集
- -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
1 | //用例 |
四、总结
由于年老代的空间不足,触发GC,但是GC无法在使用的年老代的对象,年老代空间依然不足,再次触发GC。最终调整年老代的空间大小,调整了下bin目录下Catania.sh中jvm的配置,问题就解决了。但是其过程也是收获很多知识的。还有很多值得我们探索,GC的算法,jvm调优等问题。